
ビックデータ解析ソリューション(Redshift構築)
クラウド型データウェアハウス(DWH)で大きな投資無しに大量のデータを高速に解析出来ます。
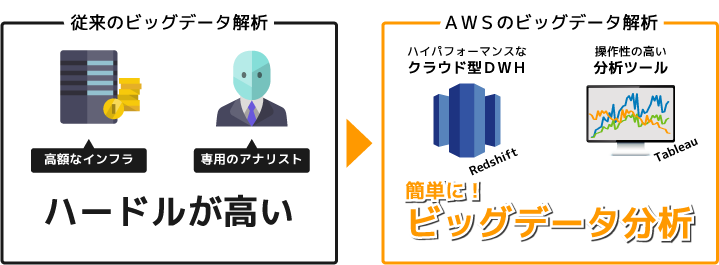
Amazon RedshiftはAWSのクラウド型データウェアハウス(DWH)サービスです。
従来ビッグデータ解析を行うためには莫大なインフラ投資を行う必要がありましたが、ハイパフォーマンスなデータウェアハウス(DWH)を月額数万円から利用することが可能です。
大量データの集計を得意としており、従来のインフラではリソースの関係で週1回しか出来なかったレポーティングの頻度を上げたり、商品ごとに集計していたデータを個々の取引ごとにするといった事が容易に出来、企業が求める詳細なデータをいつでも取得できるという特徴があります。
また、様々なBI(分析)ツールとも連携することが出来るため、データアナリストの様な専門家無しに、役員・マーケティング・営業など必要なユーザーが必要な時に自由に分析することが出来ます。
さらに、決められたフォーマット以外の切り口での分析が行えるため、既にあるデータをより有効活用することが出来ます。
Redshiftの主な特徴
| 1 | カラムナー(列指向) データベース |
通常のDBは行指向DBと呼ばれ、行毎に処理されるため主にトランザクション処理向きですが、カラムナー(列指向)型DBは分散処理向きで、大量のデータを集計することに向いています。 |
|---|---|---|
| 2 | 豊富な圧縮エンコード種別 | 9種類の圧縮エンコーディングに対応しており、且つそのデータの特性に応じて、一番有効なエンコーディングを自動で決定する機能があります。 |
| 3 | MPP(超並列演算) | インスタンスを追加する度にデータ容量だけでなく、処理性能も向上します。 |
| 4 | 簡単にインスタンス追加 | データ容量やパフォーマンスが足りなくなった場合などには、数クリックで自由にインスタンスを追加できます。 |
| 5 | 拡張性 | 数百GB~数PBまで拡張できます。 |
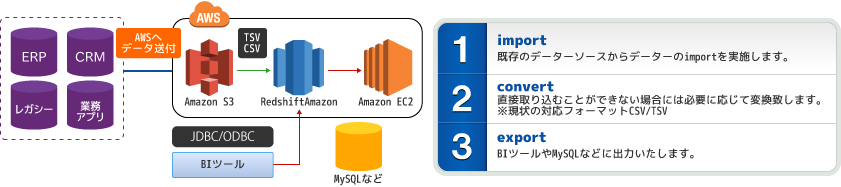
構成イメージ
Amazon EMR(Hadoop)とAmazon Redshiftの比較
| Amazon EMR(Hadoop) | Amazon Redshift |
|---|---|
| バッチ処理等短期的に利用するデータの分析処理に向いています。 | 標準的な SQL や既存の BI ツールを使用してクエリを行う、永続化が必要な大容量の構造化データに向いています。 |
| 複雑な機械学習を利用した分析など、より高度な処理はHadoopが適している場合があります。 | 数千万件、数億件というレコードも高速解析が可能です。短時間で解析でき集計や分析といった用途にも向いています。 |
提供サービス
| 初期作業 | スキーマー構築 | CSVやTSVに合わせた構造の構築、または既存DB構造をベースにした構築 |
|---|---|---|
| インポート環境構築 | S3からRedshiftへの自動差分とり込み機能の構築 | |
| 高速転送環境構築 | for Linux : tsunami,skeed(有料) for windows : skeed(有料) |
|
| 運用作業 | 障害検知・監視 | コンピューティング使用率、メモリ使用率、ストレージ使用率、インポート用S3の監視 |
| バックアップ | バックアップ/バックアップデータ管理 | |
| 障害対応 | 障害検知後、障害原因の調査から復旧まで実施致します。 | |
| 技術サポート | 技術サポート/AWSへのQA |
